ENVX1002 Statistics in Life and Environmental Sciences
Floris van Ogtrop
The University of Sydney
Apr 2026
Important Notice
The Faculty has been informed of instances where students are being targeted by illegitimate academic services, which could potentially lead to plagiarism or other breaches.
This can include:
“tutoring” services who provide assignment instructions or model answers;
using another person or company to write or complete your assignment;
using online file-sharing sites that lead to plagiarism.
Engaging in such activities could constitute a breach of the Academic Integrity Policy and may result in penalties, including failing the assignment, the unit, or even a suspension or exclusion for misconduct.
We want you to do well on assessments. Contact the Learning Hub, your tutor, or Unit Coordinator to get support.
There are resources available to help you. Don’t be afraid to ask for help.
Outline
Why do inferential statistics?
Hypothesis testing;
One-sample tests;
Confidence intervals;
Transformations.
Learning outcomes
LO1. By the end of this course, students will be able to implement basic reproducible research practices—including consistent data organization, documented code, and version-controlled workflows—so that their statistical analyses and results can be readily replicated and validated by others.
LO2. By the end of this course, students will demonstrate proficiency in utilizing R and Excel to effectively explore and describe life science datasets.
LO3. By the end of this course, students will be able to apply parametric and non-parametric statistical inference methods to experimental and observational data using RStudio and effectively interpret and communicate the results in the context of the data.
LO4. By the end of this course, students will be able to put into practice both linear and non-linear models to describe relationships between variables using RStudio and Excel, demonstrating creativity in developing models that effectively represent complex data patterns.
LO5. By the end of this course, students will be able to articulate statistical and modelling results clearly and convincingly in both written reports and oral presentations, working effectively as an individual and collaboratively in a team, showcasing the ability to convey complex information to varied audiences.
Inferential statistics
So far we have focused on Exploratory Data Analysis EDA;
EDA helps us describe and visualise data;
Inferential statistics takes the next step: using a sample to learn about a population;
This is an important and sometimes difficult step in statistics;
Because samples vary by chance, we need formal methods to decide whether an observed difference is likely to reflect the real effect.
Hypothesis testing
In statistics, a hypothesis is a claim about a population parameter.
We often begin with a benchmark or reference value
We then ask:
Is our sample consistent with that claim, or is the difference too large to plausibly due to chance alone?
Hypothesis testing
Suppose the guideline value for Total Nitrogen (TN) at a site along a river is \(500 \mu g/L\)
We might ask
Is the mean TN concentration at this site equal to \(500 \mu g/L\), or is it different?
This gives us a natural hypothesis test:
Null hypothesis\(H_0:\) the mean TN concentration is \(500 \mu g/L\)
Alternative hypothesis\(H_1:\) the mean TN concentration is NOT\(500 \mu g/L\)
Should we move away from an over reliance on p-values towards more robust statistical methods and a greater emphasis on the size and reproducibility of effects?
Look up terms like “P Hacking”…
C: Conclusion
At the end of a statistical test we write two conclusions
A statistical conclusion based on the test statistic, confidence intervals, p-value and the level of significance i.e. we reject or fail to reject \(H_0\)
A scientific (biological) conclusion what does this mean in the context of the study.
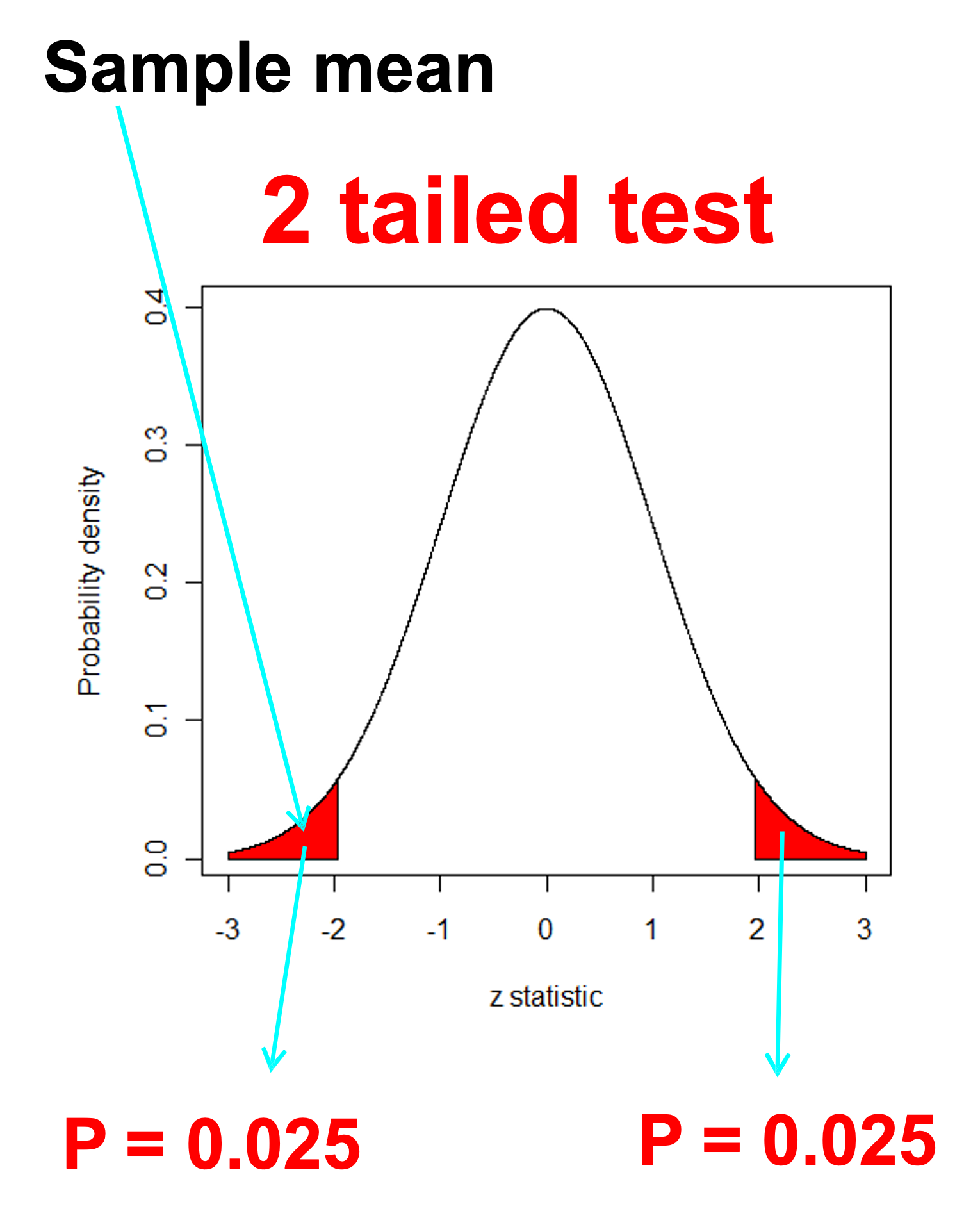
One or Two - Tails
One or Two - Tails
Suppose we want to compare a sample population or sample mean \((\mu)\) to a benchmark value \((c)\) - Could be our water quality benchmark of \(c=500 \mu g/L\)
\(H_0:\mu=c\)Two tailed
\(H_1:\mu \ne c\)Two tailed
\(H_0:\mu \ge c\)One tailed - less than
\(H_1:\mu < c\)One tailed - less than
\(H_0:\mu \le c\)One tailed - greater than
\(H_1:\mu > c\)One tailed - greater than
We usually use the first (two tailed) form unless we are specifically interested in testing whether the difference is in one direction because this is the only direction of interest
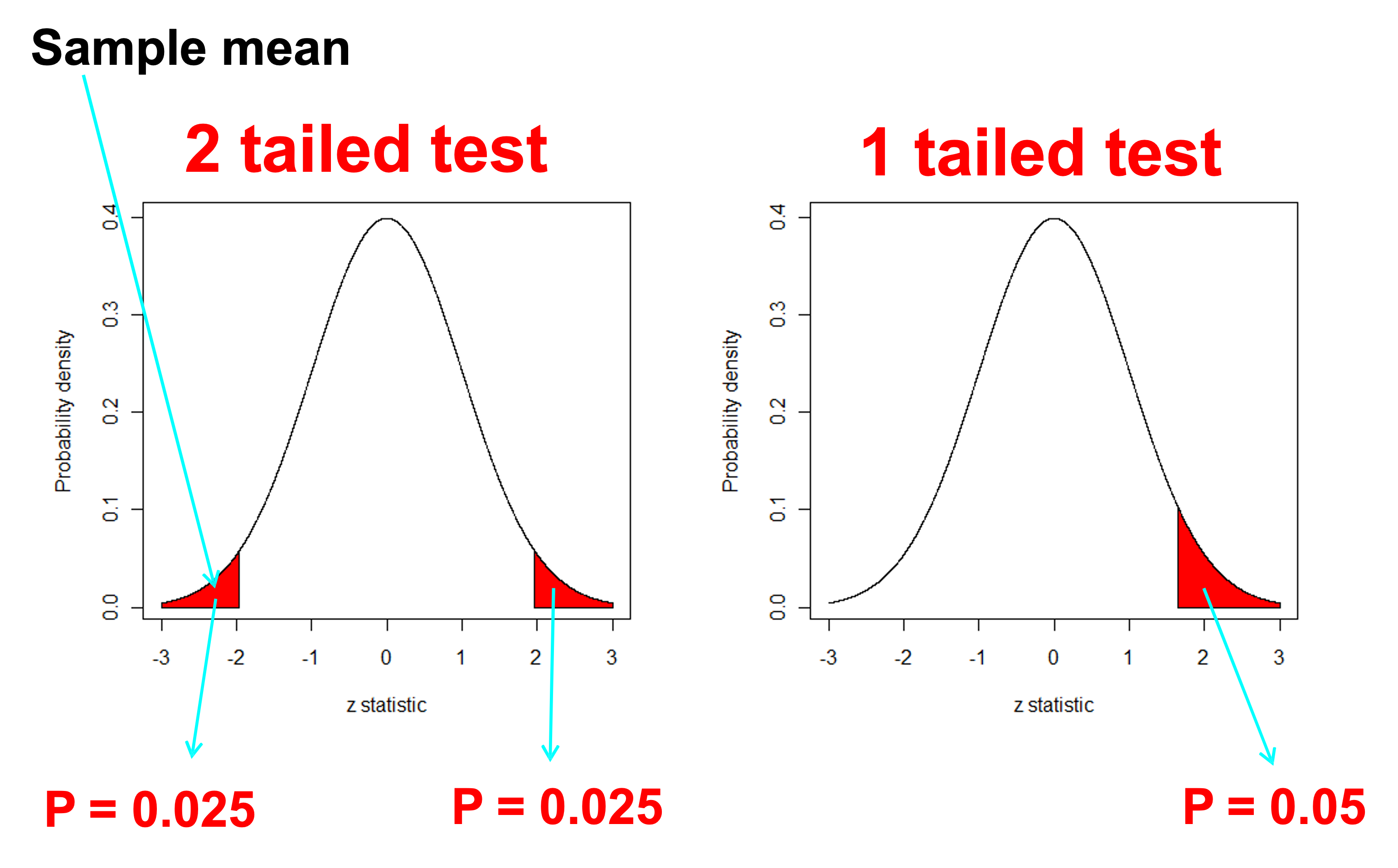
One-tailed tests (water quality)
Goal
Hypotheses
Tail
Detect unsafe water
H₀: μ ≤ c, H₁: μ > c
Right
Demonstrate safe water
H₀: μ ≥ c, H₁: μ < c
Left
Rule: The tail follows the alternative hypothesis (H₁)
Type one or type two error
Type I error
False positive: we reject H0 when it is true
Type II error
False negative: we accept H0 when it is false
Note: Decreasing the significance level (\(\alpha\)) to say 0.01 will increase the probability of type II error
Sample size and power
Power is the probability a test will detect a real effect when one exists.
High power means a low chance of type II error;
Low power means a higher chance of missing a real effect.
In general:
larger sample sizes increase power;
smaller standard deviations increase power;
larger effects are easier to detect.
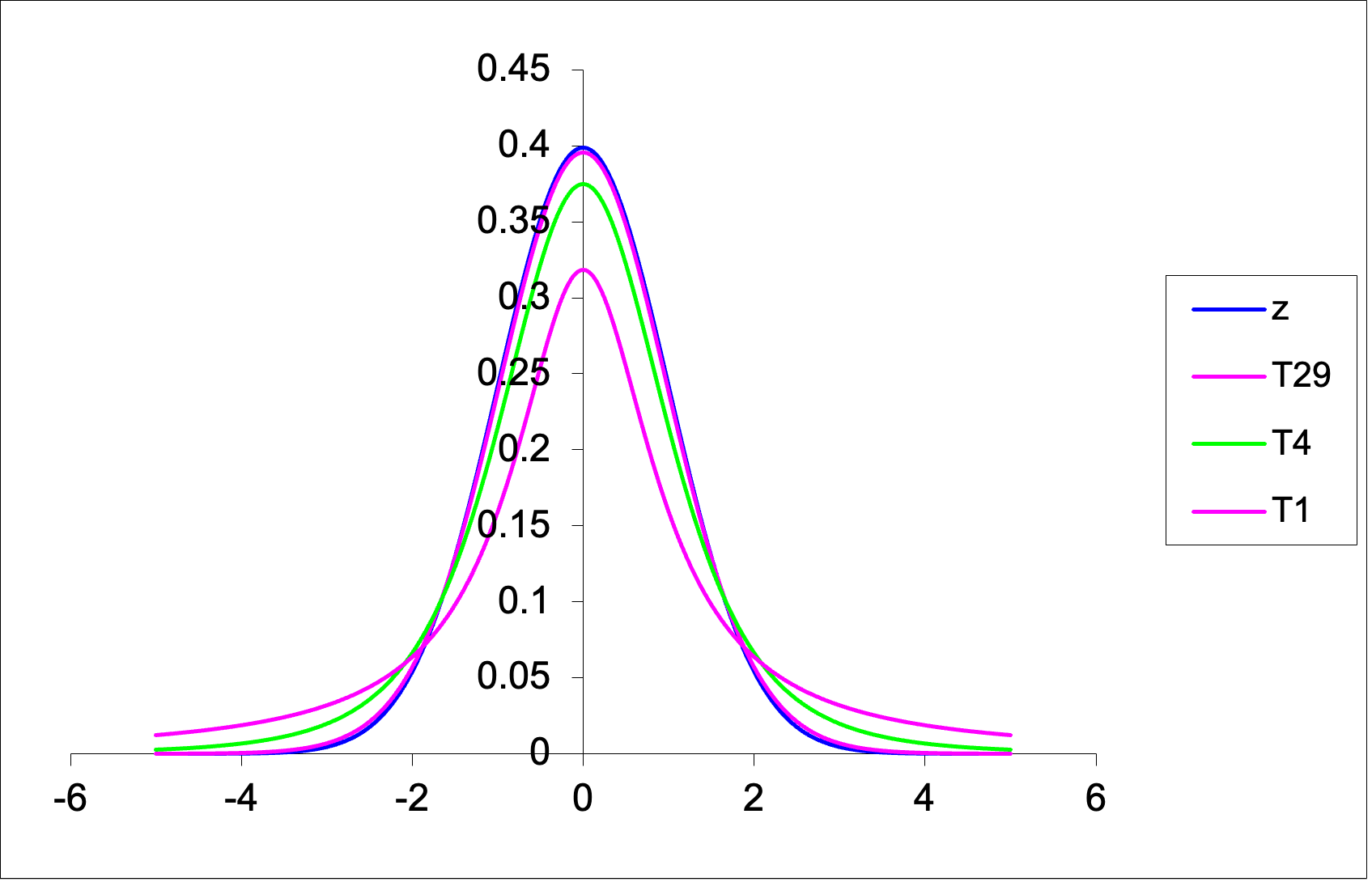
The t-distribution
The t-distribution is:
bell-shaped;
symmetric;
centred on zero;
similar in shape to the normal distribution, but with heavier tails.
Its exact shape depends on the degrees of freedom
For a one-sample t-test \(df=n-1\) where n is the sample size.
As the sample size increases, the t-distribution becomes more similar to the normal distribution.
Comparing the shapes of the Student’s T and the Z (normal) curve
Class exercise: One sample t-test
Suppose we wish to test whether the mean resting heart rate of ENVX1002 students differs from a benchmark value of 70 beats per minute (bpm).
We are going to do this exercise in class but I have provided a simulated example below so you have it in the slides as well.
Class exercise: One sample t-test
We will simulate some data for 30 students in our ENVX1002 class. To do this we will draw 30 random numbers from a normal distribution with a mean of 70 and a standard deviation of 10.
Code
set.seed(1974)heart_rate <-rnorm(30, mean =70, sd =10)
Before applying a one-sample t-test, we should check whether the sample is approximately normally distributed. Consider the following:
Sample size
Histogram
Q-Q plot
Jitter plot
Boxplot
Shapiro test
Small (n < 30)
Limited
Best
Very useful
Useful
Cautious use
Medium (30–100)
Useful
Very useful
Useful
Useful
Sometimes useful
Large (n > 100)
Useful
Best
Less useful
Good (outliers)
Too sensitive
Rule of thumb:
- Small n: show the data (jitter) + Q-Q plot
- Larger n: histogram + Q-Q plot
- Use boxplots to highlight spread and outliers, not normality alone
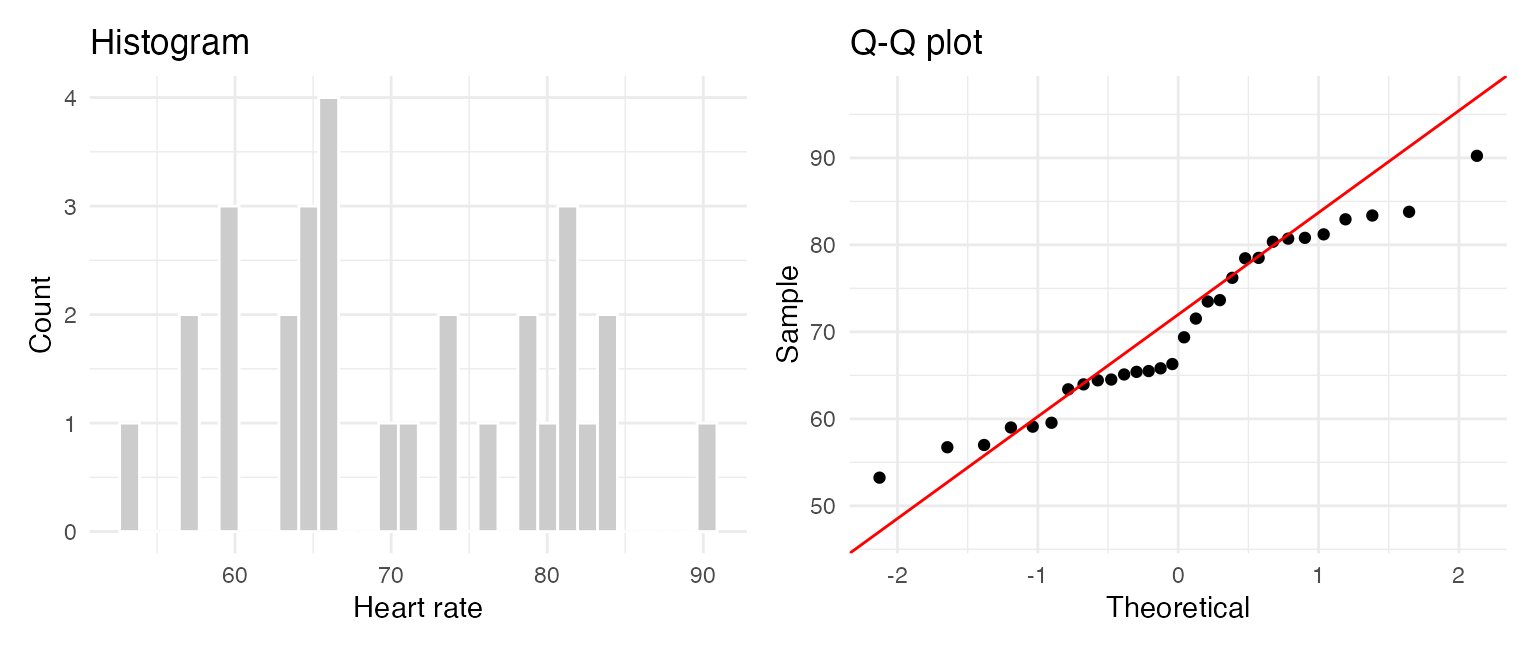
Class example: Assumptions
We begin by looking at the data (EDA). Our sample size is 30 so we can look at the histogram, Q-Q plot and jitter plot.
Code
library(ggplot2)library(patchwork)df <-data.frame(heart_rate)p1 <-ggplot(df, aes(heart_rate)) +geom_histogram(fill ="grey80", colour ="white", bins =30) +labs(title ="Histogram", x ="Heart rate", y ="Count") +theme_minimal()p2 <-ggplot(df, aes(sample = heart_rate)) +stat_qq() +stat_qq_line(colour ="red") +labs(title ="Q-Q plot", x ="Theoretical", y ="Sample") +theme_minimal()p1 + p2
Class example: Assumptions
As an option, we can also use the Shapiro-Wilk test as a supporting check. Best if the sample size is less than 50.
If (p > 0.05), we do not have strong evidence against normality;
This does not prove normality, but suggests the t-test may be reasonable.
Code
shapiro.test(heart_rate)
Shapiro-Wilk normality test
data: heart_rate
W = 0.95114, p-value = 0.1814
One Sample t-test
data: heart_rate
t = 0.25373, df = 29, p-value = 0.8015
alternative hypothesis: true mean is not equal to 70
95 percent confidence interval:
66.76984 74.14513
sample estimates:
mean of x
70.45748
We can see the following output:
the t-statistic = 0.25373
the degrees of freedom = 29 \((n-1)\)
the p-value = 0.8015
the 95% confidence interval = (66.76984 74.14513)
the sample mean = 70.45748
Class example: Conclusion
Statistical conclusion
Because (p = 0.8015 > 0.05), we fail to reject the null hypothesis.
Scientific conclusion
The data do not provide strong evidence that the mean resting heart rate of ENVX1002 students differs from 70 bpm.
Also note: - 70 bpm lies within the 95% confidence interval - this is consistent with the non-significant test result
Confidence intervals
A confidence interval gives a range of plausible values for an unknown population parameter.
Many people prefer confidence intervals because they show:
the estimated value
the uncertainty around that estimate
A hypothesis test gives a decision about a claim. A confidence interval gives a plausible range.
Confidence intervals - known variance
Assuming our sample comes from a normal population, we can calculate the confidence interval for the mean of a population when the population variance is known. An example may be in manufacturing where we know the variance of a process.
qt(0.975, df =29) ## in our heart rate example, n=30 so df = 29
[1] 2.04523
Confidence intervals - Unknown variance
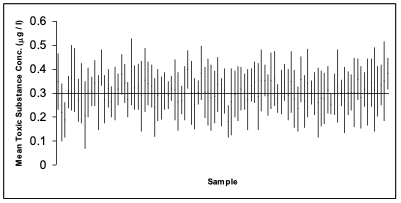
The following is simulation of 100 studies, each containing n = 6 observations of a fictitious toxic substance concentration (\(\mu g / l\)) assumed to be \(\sim N(0.3, 0.12)\).
For each sample the 95% confidence interval calculated:
Depiction of confidence intervals from each of 100 simulated samples
Confidence intervals - Unknown variance
In the graph on the previous slide, a confidence interval includes the true mean value of 0.3 if the vertical line (representing the width of the CI) crosses the horizontal line.
We have to accept that 5% of the time we will not capture the true mean.
We can widen the confidence interval to 99% so we are more confident but this can increase the chance of a type II error.
Example 2: Water Quality
Let’s look at our water quality example again:
The data is Total Nitrogen (TN) levels @ Wallacia in western Sydney on the Nepean River
According to the ANZECC guidelines, the maximum acceptable level of TN in an lowland river is 500 \(\mu g/L\) and for an upland river = 250 \(\mu g/L\). (see Table 3.3.2 in Australian and New Zealand Guidelines for Fresh and Marine Water Quality)
We want to know if the observed mean value of TN in our sample is different to the guideline value of 500 \(\mu g/L\)
Code
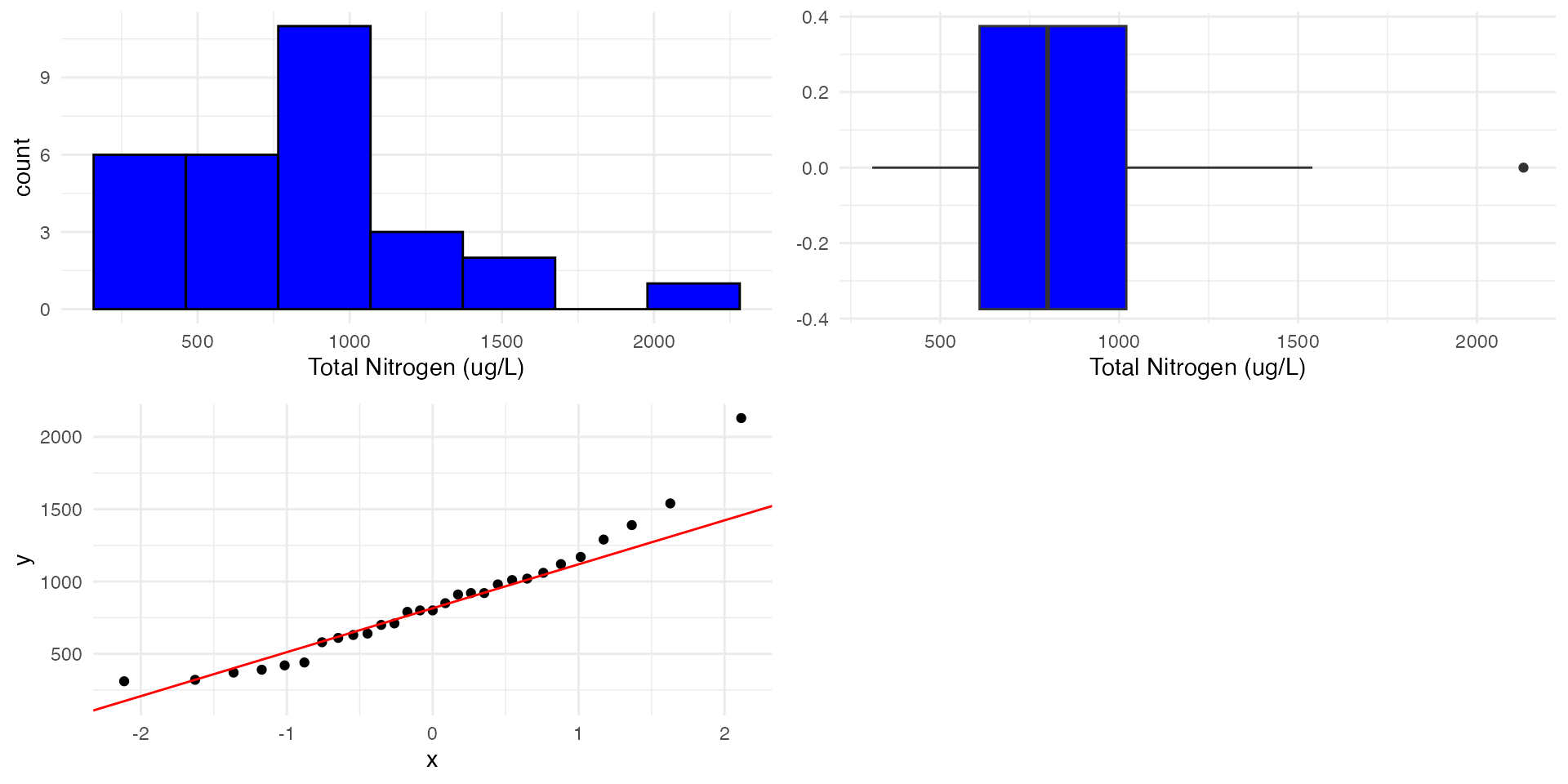
TN <-read.csv("data/TN_Wallacia.csv")str(TN)
'data.frame': 29 obs. of 1 variable:
$ TN: int 1020 1120 1170 920 920 1010 850 910 800 710 ...
# Arrange the plots in a 2x2 layoutgrid.arrange(p1, p2, p3, ncol =2)
Example 2: Check assumptions
Shapiro-Wilk normality test
For smaller sample sizes, we can use the Shapiro-Wilk test (say < 50) to confirm whether the data is normally distributed or not.
Code
shapiro.test(TN$TN)
Shapiro-Wilk normality test
data: TN$TN
W = 0.92582, p-value = 0.04293
We see P<0.05 so we reject the null hypothesis that the data is normally distributed.
For really large samples (>>30) the central limit theorem suggests that the distribution of the sample means tends to be normal. However, extreme skewness, heavy tails, or outliers can still affect the test’s performance.
Example 2: Transformations
For right (positive) skewed data, we can use a
\(1/x\) inverse transformation for highly skewed data.
\(\log_{10}\) or \(\log_e\) transformation for very skewed data.
\(\sqrt{x}\) square root transformation for moderately skewed data.
For left (negative) skewed data (which is rare to find), we can “try” a
\(x^2\), \(x^3\) or \(e^x\) transformation.
Example 2: Transformations & Recheck assumptions
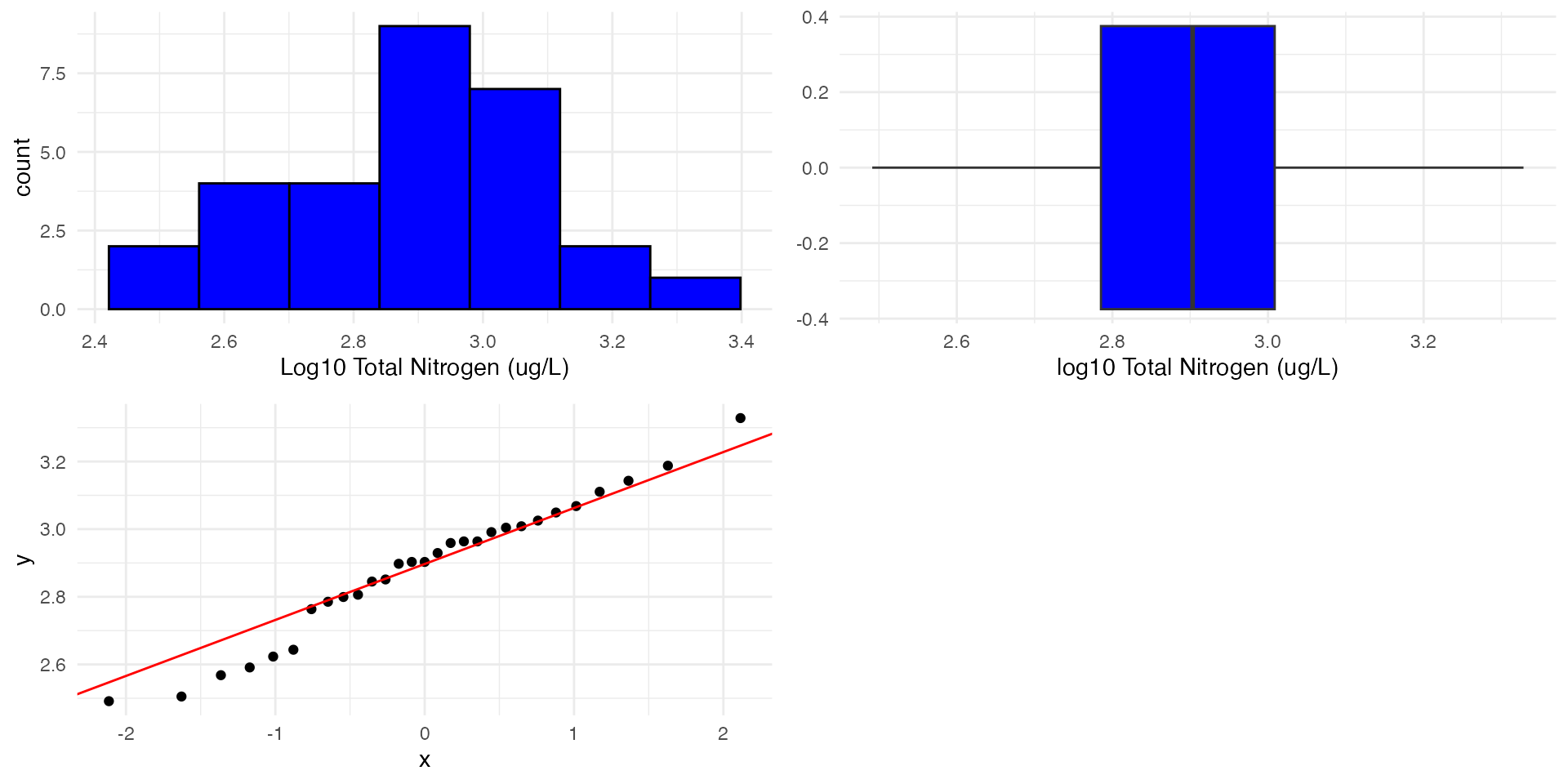
Let’s try a log10 transformation:
We start by creating a new column in our data frame called log10_TN
We then take the log10 of the TN column and store it in the new column - note we could also use “mutate” from the dplyr package to do this.
One Sample t-test
data: TN$log10_TN
t = 4.8768, df = 28, p-value = 3.884e-05
alternative hypothesis: true mean is not equal to 2.69897
95 percent confidence interval:
2.807748 2.965309
sample estimates:
mean of x
2.886528
The p-value is <0.001 (3.d.p.) which is less than 0.05. Therefore, we reject the null hypothesis.
There is strong evidence that the mean value of TN in Nepean River is different to 500 ug/L.
Can we say something about the direction??
Example 2: Geometric mean & Confidence intervals
Geometric mean
Note that now we are looking at the geometric mean as opposed the the arithmetic mean which was 855.86 in our case
Code
10^mean(TN$log10_TN)
[1] 770.0666
Confidence intervals
We need to back transform the confidence interval to the original scale.
To back-transform the confidence interval we can use the following:
\(10^{CI_{low}}\) and \(10^{CI_{high}}\)
Code
10^(2.81)
[1] 645.6542
Code
10^(2.97)
[1] 933.2543
This means that we are 95% confident that the geometric mean (back-transformed mean) of the sample is between approximately 646 and 933 ug/L. This is higher than the hypothesised mean.
Example 2: Conclusion
The data was log10 transformed to meet the assumptions of the t-test.
We have strong evidence that the mean value of Total Nitrogen in Nepean River is different to 500 ug/L.
We are 95% confident that the geometric mean (back-transformed mean) of the sample is between approximately 646 and 933 ug/L.
Looking at the confidence interval, we can say that the mean value of TN in Nepean River is significantly greater than 500 ug/L.
Example 3: One tailed test
We can also use a one tailed test if we are specifically interested in whether the observed value is greater or less than the expected value.
In this case we only want to know if the TN concentration is greater than the ANZECC guidelines of 500 \(\mu g/L\).
One Sample t-test
data: TN$log10_TN
t = 4.8768, df = 28, p-value = 1.942e-05
alternative hypothesis: true mean is greater than 2.69897
95 percent confidence interval:
2.821104 Inf
sample estimates:
mean of x
2.886528
P < 0.001 (3.d.p.) so we reject the null hypothesis.
Because we are doing a one tailed test we can now conclude that the mean value of TN in Nepean River is greater than \(\log_{10}(500)\)\(\mu g/L\)
Take a look at the confidence interval and the p-value. What do you notice when comparing to the two tailed test?