Lecture 03b – One-way ANOVA
ENVX2001 Applied Statistical Methods
Apr 2026
The experiment

We need a method that handles more than two groups. Consider a new experiment:
- 20 chicks are randomly assigned to one of 4 diets
- 5 replicates per diet
- Response: weight gain (g)
Are there differences?
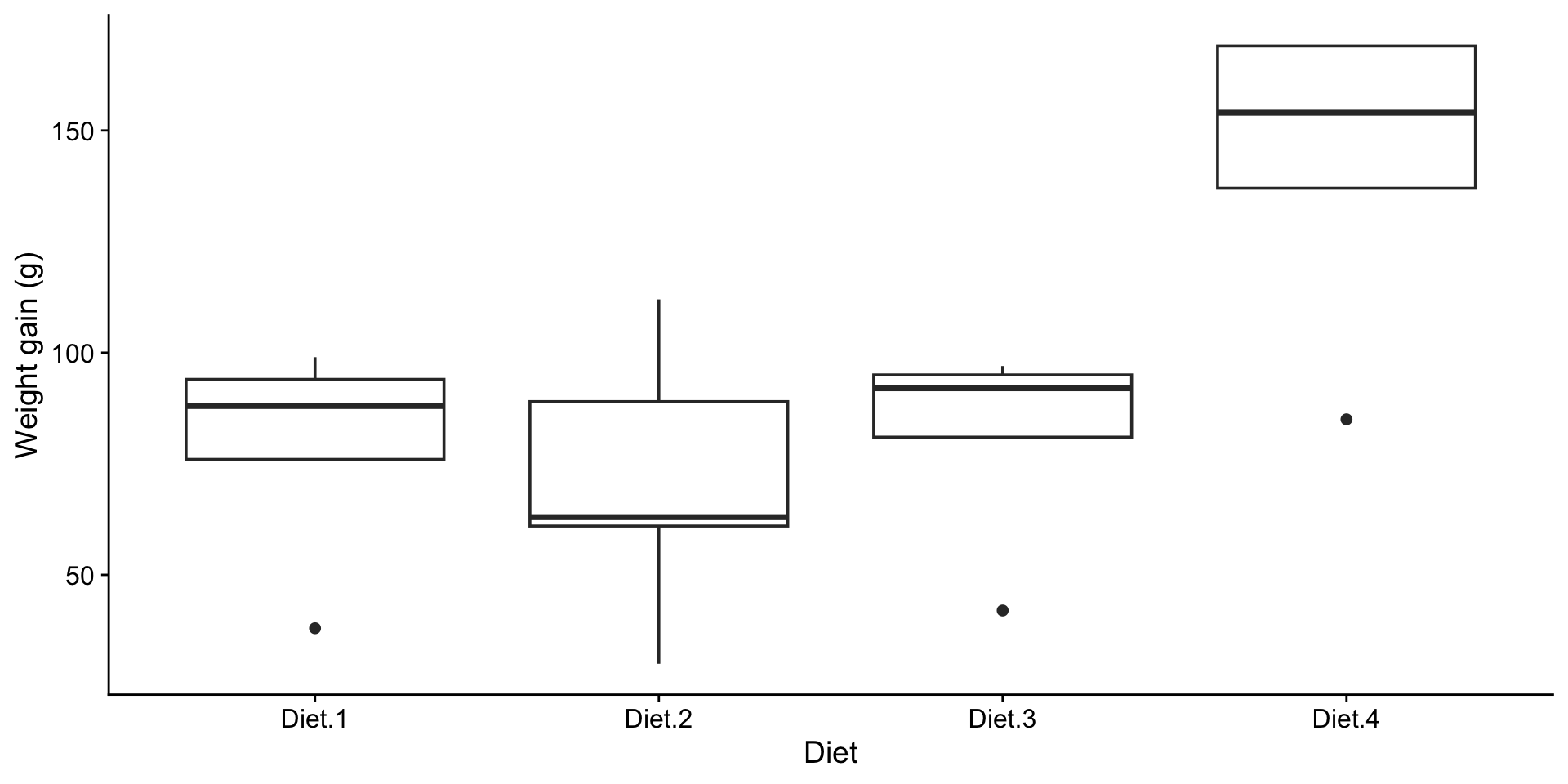
What do the boxplots suggest?
A: Residual diagnostics
Code
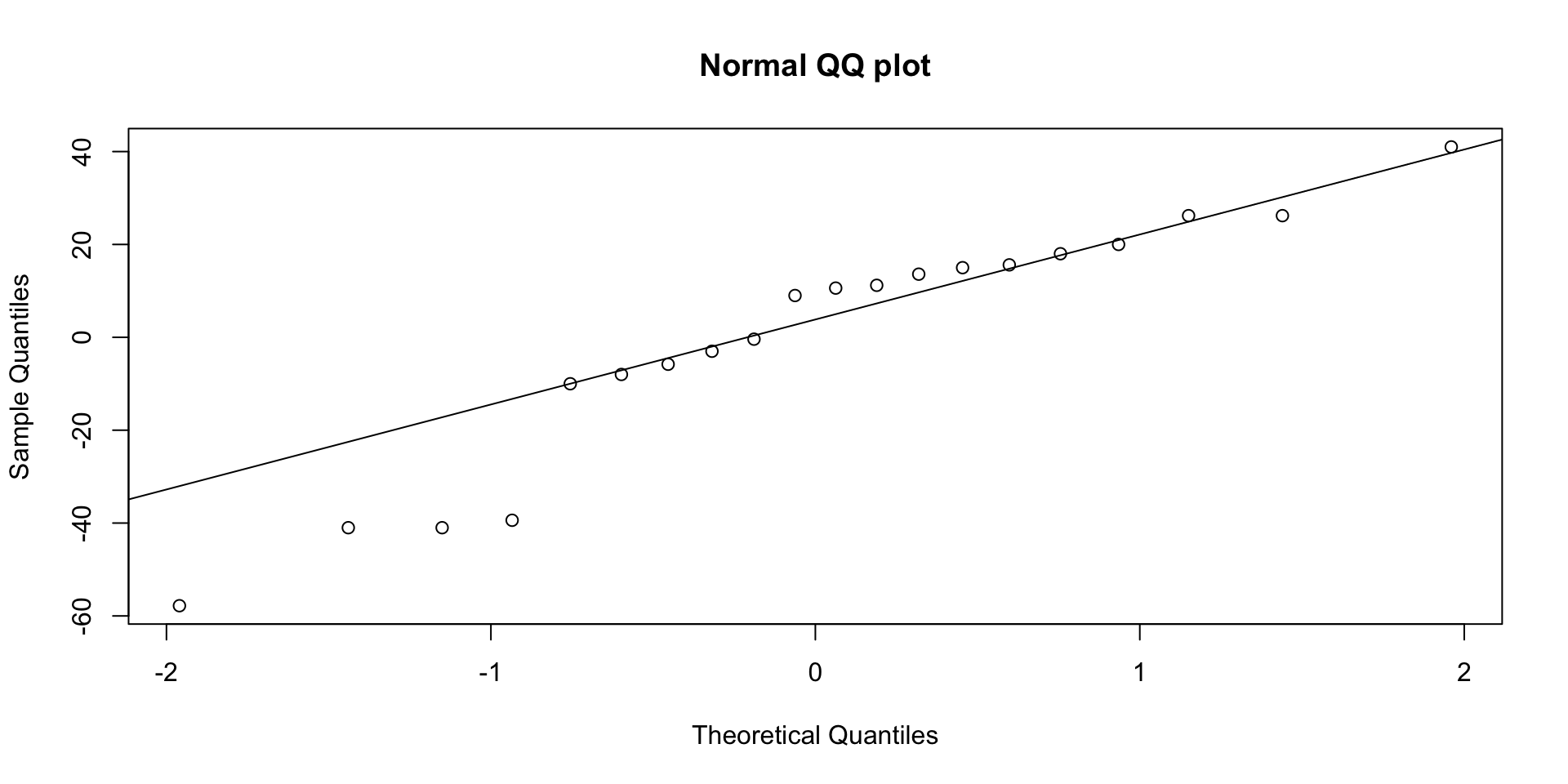
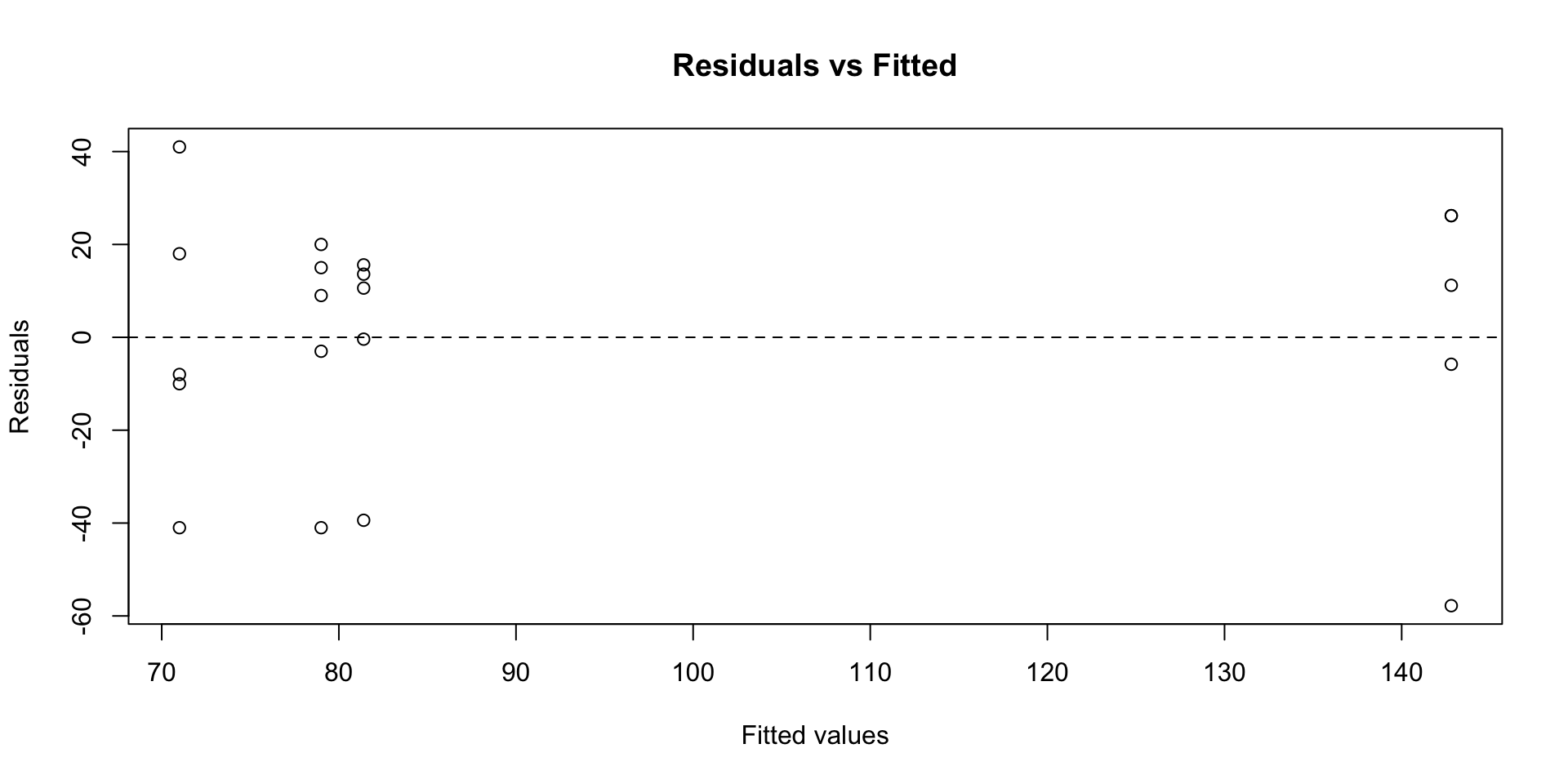
- QQ plot: points follow the line, supporting normality
- Residuals vs fitted: no fan shape, supporting equal variances
- Independence holds by design: each chick is measured once
T: The ANOVA idea
- How does ANOVA decide whether these four diets differ?
- If diets matter, differences between groups should be large relative to variation within groups
Code
overall_mean <- mean(chicks$weight)
group_means <- chicks |>
group_by(diet) |>
summarise(mean_wt = mean(weight))
p1 <- ggplot(chicks, aes(diet, weight)) +
geom_point(size = 3, alpha = 0.6) +
geom_hline(data = group_means, aes(yintercept = mean_wt),
linetype = "dashed", colour = "#e64626", linewidth = 0.8) +
labs(title = "Four group means", x = "Diet", y = "Weight gain (g)") +
cowplot::theme_cowplot()
p2 <- ggplot(chicks, aes(diet, weight)) +
geom_point(size = 3, alpha = 0.6) +
geom_hline(yintercept = overall_mean, colour = "#e64626",
linewidth = 0.8, linetype = "dashed") +
labs(title = "One overall mean", x = "Diet", y = "Weight gain (g)") +
cowplot::theme_cowplot()
library(patchwork)
p1 + p2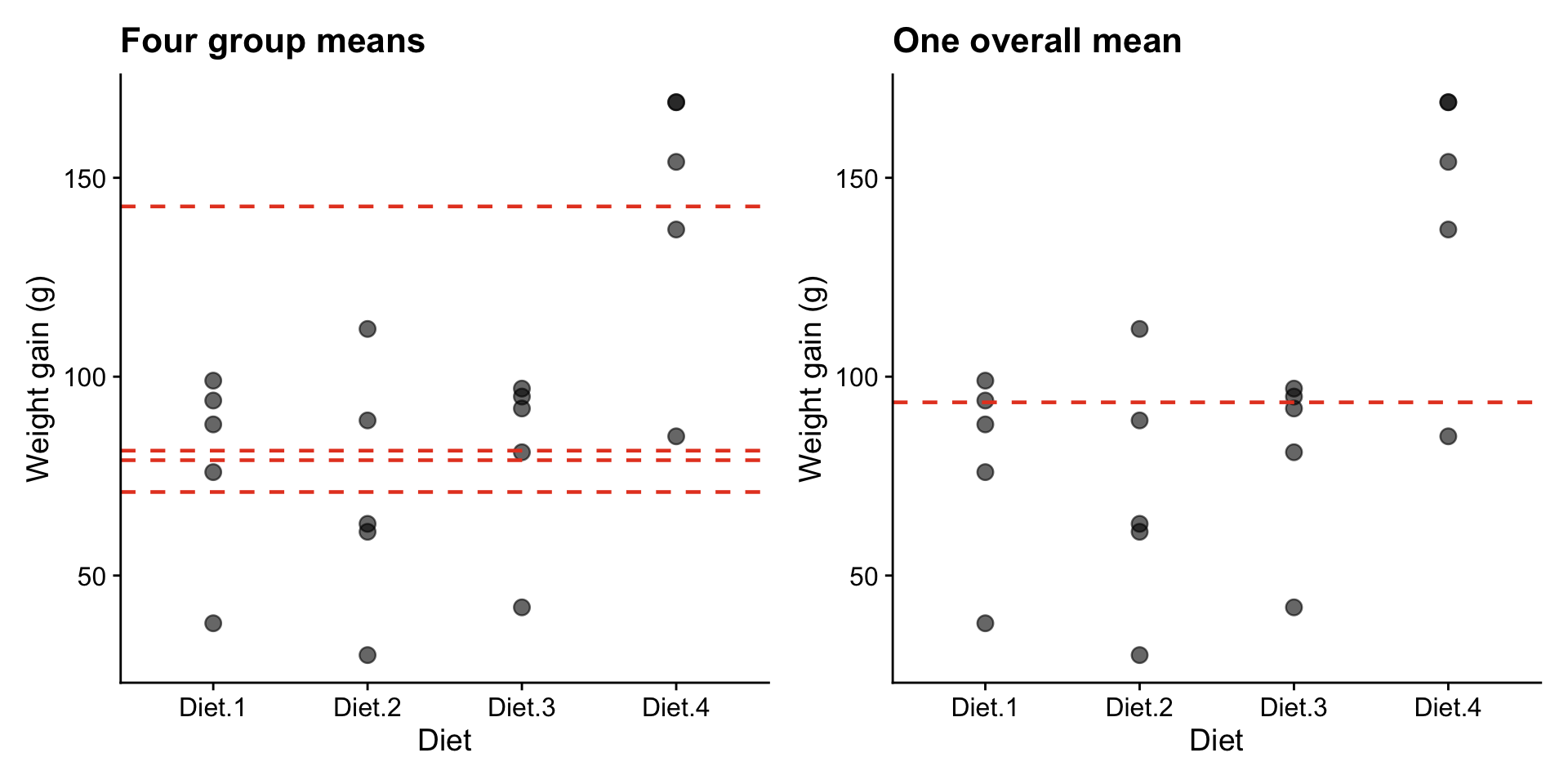
Do four separate means (left) explain the data better than a single overall mean (right)?
Visualising the comparisons
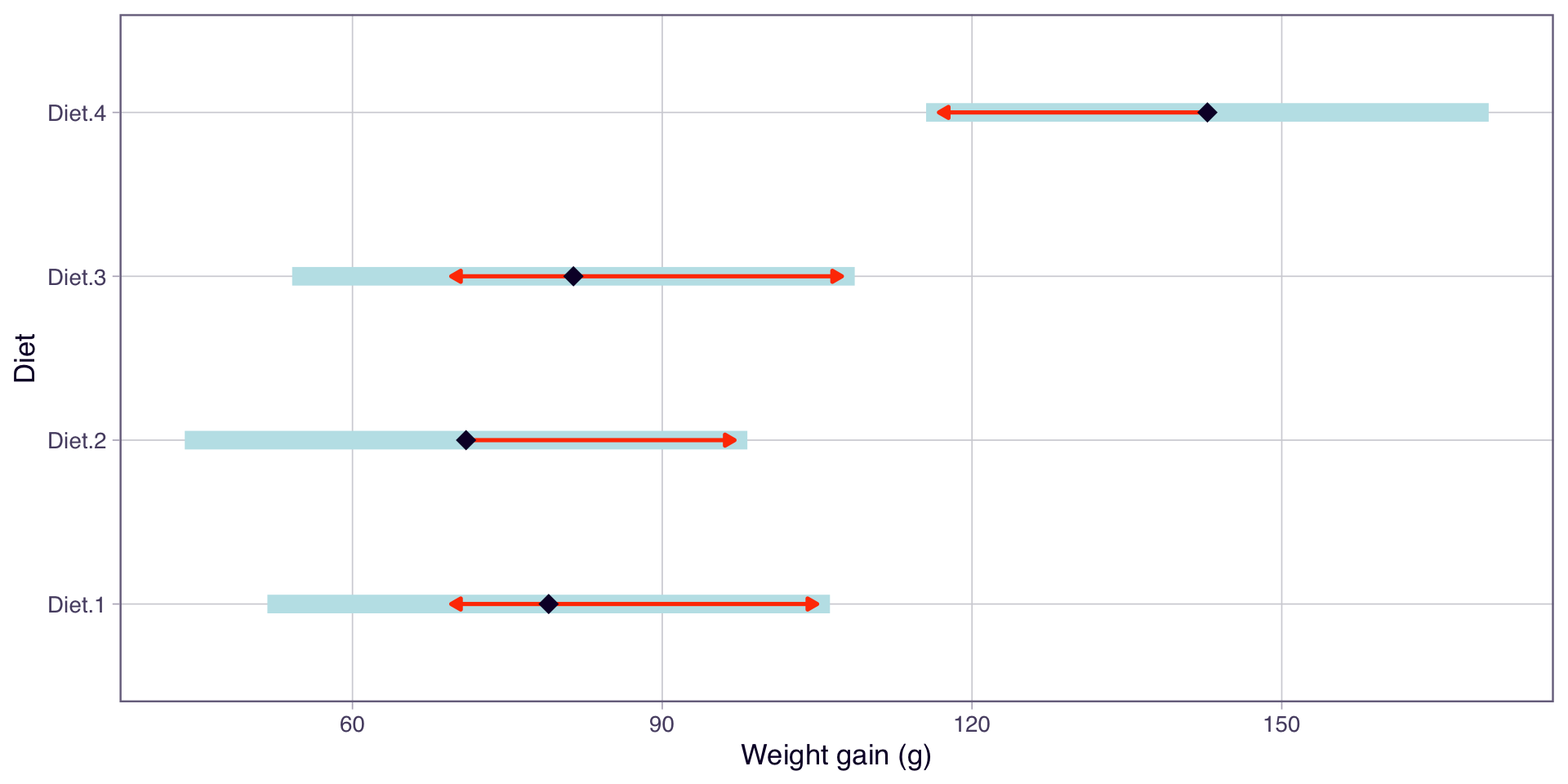
- Each point is the estimated mean for that diet
- The arrows represent comparison intervals (adjusted CIs)
- Groups with overlapping arrows are not significantly different
- We will cover post-hoc methods in more detail next week